Proses dalam Data Mining
Untuk melaksanakan project-project dalam Data Mining (DM) secara sistematis, suatu proses yang umum berlaku biasanya diterapkan. Berdasarkan ‘best practice’, para praktisi dan peneliti DM mengusulkan beberapa proses (workflow atau pendekatan step-by-step yang sederhana) untuk memperbesar peluang keberhasilan dalam melaksanakan project-project DM. Usaha-usaha itu akhirnya menghasilkan beberapa proses yang dijadikan sebagai standard, beberapa diantaranya (yang paling popular) dibahas dalam bagian ini. [Baca juga: Metode-metode dalam Data Mining]
Salah satu proses yang sudah dijadikan standard tersebut dan boleh dibilang sebagai yang paling populer, yaitu ‘Cross-Industry Standard Process for Data Mining’ – atau CRISP-DM – telah diusulkan pada pertengahan 1990an oleh konsorsium perusahaan-perusahaan eropa untuk dijadikan methodology standard non-proprietary bagi DM (CRISP-DM, 2009). Gambar berikut di bawah ini menggambarkan proses yang diusulkan tersebut, yang merupakan enam tahap berurutan yang dimulai dengan pemahaman bisnis yang baik dan perlunya project DM dan berakhir dengan ‘deployment’ solusi yang memuaskan kebutuhan bisnis tertentu.
 |
| Enam tahap proses CRISP-DM dalam data mining |
Meskipun langkah-langkah tersebut pada dasarnya berurutan, tetapi pada umumnya ada banyak sekali ‘backtracking’ (pelacakan kembali ke belakang). Karena DM didorong oleh pengalaman dan eksperimen, bergantung pada situasi problem saat itu dan pengetahuan/pengalaman dari si analis, maka proses secara keseluruhan bisa sangat iterative (berulang-ulang, misalnya seseorang harus bergerak maju mundur dalam langkah-langkah di atas beberapa kali) dan memakan waktu. Karena langkah-langkah berikutnya dibuat berdasarkan hasil-hasil dari langkah-langkah sebelumnya, maka kita harus menaruh perhatian lebih pada langkah-langkah awal supaya tidak menempatkan seluruh kajian pada jalur yang salah sejak awal.
Langkah 1: Pemahaman terhadap bisnis (Business Understanding)
Elemen kunci dari kajian DM apapun adalah mengetahui secara pasti untuk apa kajian tersebut dilakukan. Untuk menjawab pertanyaan ini sebaiknya dimulai dengan suatu pemahaman yang lengkap mengenai kebutuhan manajerial terhadap knowledge baru dan suatu spesifikasi eksplisit dari tujuan bisnis mengenai kajian yang dilakukan. Tujuan-tujuan spesifik seperti berikut diperlukan: “Apakah ciri-ciri umum dari pelanggan yang pindah ke kompetitor akhir-akhir ini?” atau “Bagaimanakah profil khusus dari pelanggan kita, dan berapa nilai yang mereka berikan kepada kita?”. Kemudian rencana project untuk menemukan knowledge seperti itu dibuat sehingga akhirnya menetapkan orang-orang yang bertanggungjawab untuk mengoleksi data, menganalisa data, dan melaporkan temuan-temuan yang didapatkan. Pada tahap yang sangat awal ini, budget untuk mendukung kajian ini seharusnya juga ditetapkan, paling tidak pada tingkat atas dengan jumlah angka kasar.
Langkah 2: Pemahaman terhadap data (Data Understanding)
Kajian dalam DM adalah khusus membahas mengenai suatu pekerjaaan bisnis yang sudah terdefinisi dengan baik, dan pekerjaan-pekerjaan bisnis yang berbeda memerlukan ‘set-data’ yang berbeda pula. Setelah pemahaman terhadap bisnis, aktivitas utama dari proses DM berikutnya adalah mengidentifikasi data yang relevan dari berbagai database yang ada. Beberapa poin kunci harus dipikirkan dalam proses identifikasi data dan fase pemilihan (data). Yang pertama dan yang terpenting adalah bahwa sang analis harus jelas dan padat mengenai deskripsi pekerjaan DM sehingga data yang relevan bisa identifikasi. Contohnya, project DM untuk retail mungkin ingin mengetahui mengenai perilaku belanja para wanita penggemar belanja yang membeli baju-baju untuk musiman berdasarkan demografis mereka, transaksi kartu kredit mereka, dan ciri-ciri sosioekonomi mereka. Lebih lanjut lagi, sang analis harus membangun pemahaman yang mendalam mengenai berbagai sumber data (misalnya, dimana data yang relevan tersebut disimpan dan dalam bentuk apa; bagaimana proses mengumpulkan data—otomatis versus manual; siapa saja yang mengumpulkan data dan seberapa sering data di-update) dan berbagai variable (misalnya, variabel-variabel apa sajakah yang paling relevan? Apakah ada variable-variabel yang sinonim dan/atau homonym? Apakah variabel-variabel itu tidak bergantung satu sama lain—apakah mereka berdiri sendiri sebagai sumber informasi yang lengkap tanpa tumpang tindih atau bertentangan satu sama lain?).
Supaya memahami data dengan lebih baik, sang analis harusnya sering menggunakan berbagai macam teknik statistik dan grafik, seperti ringkasan statistic sederhana (misalnya, untuk variabel numerik adalah nilai rerata/average, nilai minimum/maksimum, nilai tengah/median, deviasi standar/standard deviation, sedangkan untuk variabel kategori adalah tabel modus/nilai yang sering muncul dan frekwensi), analisa korelasi, scatter-plots (diagram kartesian), histograms (diagram batang), dan box-plots (diagram kotak). Identifikasi dan pemilihan sumber data yang jeli dan variabel-variabel yang relevan bisa memudahkan algoritma-algoritma yang digunakan dalam DM untuk menemukan secara cepat pola-pola knowledge yang bermanfaat.
Sumber data untuk proses pemilihan data bisa bermacam-macam. Normalnya, sumber data untuk aplikasi bisnis meliputi data demografi (seperti pendapatan/income, pendidikan/education, jumlah anggota rumah tangga, dan usia), sosiografi (seperti hobby, keanggotaan klub, dan entertainment), data transaksi (catatan penjualan, jumlah belanja menggunakan kartu kredit, jumlah cek uang dikeluarkan), dan seterusnya.
Data bisa dikategorikan sebagai kuantitatif dan kualitatif. Data kuantitatif diukur dengan nilai-nilai numerik. Data tersebut bisa berupa bilangan diskrit (seperti integer atau bilangan bulat) atau bilangan kontinyu seperti bilangan decimal atau pecahan). Data kualitatif, atau disebut juga data kategori, meliputi data nominal dan ordinal. Data nominal berisi data yang tak-diurutkan dan terbatas (misalnya, data gender yang hanya memiliki dua nilai: laki-laki dan perempuan). Data ordinal memiliki nilai yang di-urut-kan dan terbatas. Contohnya, ratings kredit pelanggan adalah data ordinal karena ratings bisa berupa ‘excellent’, ‘fair’, dan ‘bad’. [silahkan baca: Jenis-jenis Atribut Data dalam Data Mining]
Data kuantitatif bisa dengan mudah disajikan dengan semacam distribusi probabilitas. Suatu distribusi probabilitas menjelaskan bagaimana data tersebar dan terbentuk. Contohnya, data yang terdistribusi normal adalah simetris dan pada umumnya disebut dengan ‘kurva bel’ (bell-shaped curve). Data kualitatif bisa saja dituliskan dalam angka-angka dan kemudian dijelaskan dengan distribusi frekwensi. Setelah data yang relevan dipilih berdasarkan tujuan bisnis DM, pra-pemrosesan data haruslah segera disiapkan.
Langkah 3: Persiapan data (Data Preparation)
Maksud dari persiapan data (atau yang lebih dikenal dengan pra-pemrosesan data) adalah mengambil data yang diidentifikasi pada tahap sebelumnya dan menyiapkan nya untuk analisa dengan menggunakan metode-metode DM. Dibandingkan dengan tahapan-tahapan lainnya dalam CRISP-DM, pra-pemrosesan data menyita waktu dan usaha paling banyak; banyak orang percaya bahwa tahap ini bertanggungjawab atas sekitar 80 persen dari total waktu yang diluangkan untuk project DM. Penyebab dari usaha yang sedemikian besar itu yang dihabiskan untuk tahap ini adalah karena data riil (di ‘real-world’) yang ada pada umumnya tidak lengkap (tidakadanya nilai pada atribut-atributnya, tidakadanya atribut tertentu yang menjadi perhatian, atau hanya berisi data yang sudah ringkas dan digabungkan), ‘noisy’ (berisi data yang error atau data yang tidak diinginkan), dan data yang tidak konsisten (berisi data yang berbeda antara kode-kode dan nama-nama). Gambar dibawah ini menunjukkan empat langkah utama yang dibutuhkan untuk mengonversi data mentah riil menjadi dataset yang bisa digali.
 |
| Tahap-tahap pra-pemrosesan data |
Pada fase pertama dari pra-pemrosesan data, data yang relevan dikumpulkan dari berbagai macam sumber yang sudah di identifikasi (yang sudah dicapai pada langkah sebelumnya—Data Understanding—dari proses CRISP-DM), berbagai data dan variabel yang diperlukan diambil (berdasarkan pemahaman yang mendalam mengenai data dan bagian-bagian yang tidak diperlukan dikeluarkan), dan berbagai macam data yang berasal dari berbagai macam sumber tadi disatukan (sekali lagi, dengan pemahaman yang mendalam mengenai data, hal-hal yang sinonim dan homonim ditangani dengan benar).
Pada fase kedua dari pemrosesan data, data dibersihkan (tahap ini juga dikenal dengan istilah data scrubbing/penggosokan data). Pada tahap ini, semua nilai-nilai dalam dataset diidentifikasi dan dipelajari. Dalam beberapa kasus, ada nilai-nilai yang kosong/hilang dan merupakan suatu anomali dalam dataset, dimana nilai-nilai itu perlu diisi (biasanya diisi dengan nilai yang memiliki kemungkinan paling besar) atau diabaikan; dan dalam kasus yang lain, nilai yang kosong/hilang adalah memang bagian dari dataset (misalnya, kolom di bagian ‘pendapatan rumah tangga’ seringkali sengaja dibiarkan kosong oleh orang-orang yang memiliki pendapatan tinggi). Pada tahap ini sang analis seharusnya juga mengidentifikasi nilai-nilai yang ‘noisy’/menggangu (misalnya data yang tidak seharusnya/data yang salah) dan mengeluarkan data tersebut. Selain itu, ketidak-konsistensian data (nilai yang tidak biasa dalam suatu variabel) seharusnya juga ditangani oleh pendapat ahli atau ‘knowledge’ dari domain yang bersangkutan.
Pada fase ketiga dari pra-pemrosesan data, data di-transformasikan demi pemrossesan yang lebih baik. Contohnya, dalam banyak kasus data di normalisasikan diantara nilai minimum dan maksimum untuk semua variabel dengan tujuan mengurangi potensi bias dari satu variabel (memiliki nilai yang sangat besar, seperti pendapatan rumah tangga) yang memiliki nilai jauh di atas variabel-variabel yang lain yang mempunyai nilai yang kecil (seperti jumlah tanggungan atau lama kerja, yang mungkin saja merupakan data yang lebih penting). Transformasi lain yang terjadi adalah ‘pendiskritan’ dan/atau agregasi. Dalam beberapa kasus, variabel-variabel numerik dikonversi menjadi nilai-nilai kategori (misalnya, ‘low’, ‘medium’, ‘high’); dalam kasus yang lain kisaran nilai unik variabel nominal direduksi menjadi dataset yang lebih kecil dengan menggunakan konsep hirarki (misalnya, daripada menggunakan data negara bagian yang berisi 50 nilai yang berbeda, orang mungkin memilih menggunakan beberapa daerah untuk suatu variabel yang menunjukkan lokasi) dengan tujuan menghasilkan dataset yang lebih cocok untuk pemrosesan komputer. Namun, dalam kasus-kasus yang lain orang mungkin memilih untuk membuat variabel-variabel baru berdasarkan yang sudah ada dengan tujuan untuk memperkuat informasi yang ditemukan dalam sekumpulan variabel dalam dataset. Contohnya, dalam dataset transplantasi organ tubuh orang mungkin saja memilih menggunakan satu variabel tunggal untuk menunjukkan kecocokkan gologan darah (1: cocok, 0: tidak-cocok) daripada harus memisah-misahkan nilai yang memiliki mutinominal untuk golongan darah baik dari si donor dan si penerima. Penyederhanaan seperti itu bisa meningkatkan isi informasi sambil mengurangi kompleksitas relasi dalam data.
Fase terakhir dari pra-pemrosesan data adalah pengurangan data (data reduction). Meskipun para penambang data senang memiliki dataset yang besar, tetapi terlalu banyak data juga akan bermasalah. Dalam pengertian yang paling sederhana, orang bisa memvisualisasikan data yang biasa digunakan dalam berbagai project DM sebagai file biasa yang berisi dua dimensi: variabel-variabel (jumlah kolom) dan kasus/records (jumlah baris). Dalam beberapa kasus (misalnya dalam project genome dan image processing dengan data microarray yang sangat kompleks), jumlah variabel bisa sangar banyak, dan sang analis harus mengurangi jumlahnya hingga bisa dikelola dengan mudah. Karena variabel-variabel diperlakukan sebagai dimensi-dimensi yang berbeda yang menjelaskan fenomena dari berbagai perspektif yang berbeda, dalam DM proses ini biasanya disebut dengan pengurangan dimensi (dimensional reduction). Meskipun tidak ada satu cara tunggal yang terbaik untuk melakukan pekerjaan ini, kita bisa menggunakan temuan-temuan dari literatur yang sudah diterbitkan sebelumnya; berkonsultasi dengan pakar dari domainnya; melakukan ujicoba statistik yang tepat (misalnya, analisa komponen utama atau analisa komponen bebas); dan lebih diutamakan, menggunakan kombinasi teknik-teknik itu untuk mengurangi dimensi-dimensi dalam data menjadi subset data yang ‘manageable’ dan relevan.
Berkaitan dengan dimensi-dimensi yang lainnya (misalnya, jumlah kasus/baris), beberapa dataset bisa saja terdiri dari jutaan atau miliaran baris. Meskipun kemampuan komputasi terus meningkat secara eksponensial, memroses jumlah baris yang sedemikian besar tersebut tidaklah praktis atau tidak layak. Dalam kasus seperti itu, kita bisa memerlukan suatu sampel dataset untuk dianalisa. Asumsi yang dijadikan dasar dari sampling tersebut adalah bahwa subset data tersebut akan berisi semua pola-pola yang relevan dari dataset yang lengkap/utuh. Dalam dataset yang homogen, asumsi yang seperti itu bisa saja terpegang dengan baik, namun data riil (real-world data) hampir tidak pernah homogen. Sang analis haruslah extra hati-hati dalam memilih subset data yang mencerminkan esensi data yang utuh dan tidak spesifik ke suatu subgroup atau subkategory. Data tersebut biasanya diurutkan pada suatu variabel, dan mengambil bagian data tersebut dari atas ke bawah bisa saja menghasilkan dataset yang ‘biased’ (tidak berimbang) pada nilai-nilai tertentu dari variabel yang sudah diindeks; karena itu, kita harus selalu mencoba untuk memilih secara acak baris-baris pada sample-set. Untuk ‘skewed data’ (tidak seimbang dan tidak linear), pengambilan sampling random secara langsung masihlah kurang, dan untuk sampling yang bertingkat-tingkat (berbagai subgroup yang berbeda-beda tetapi proporsional di dalam data yang disajikan dalam sampel dataset) mungkin saja harus diterapkan. Berbicara mengenai ‘skewed data’; sebaiknya dilakukan proses untuk menyeimbangkan data yang sangat ‘tidak seimbang’ tersebut baik dengan cara ‘oversampling’ (membuat sampling yang banyak) pada bagian kelompok data yang kurang atau ‘under sampling’ (membuat sedikit sampling) untuk bagian data yang banyak. Penelitian menunjukkan bahwa dataset yang ‘diseimbangkan’ cenderung menghasilkan model perdiksi yang lebih baik dibandingkan dengan yang ‘tidak diseimbangkan’.
Esensi dari pra-pemrosesan data diringkas dalam table dibawah ini, dengan memetakkan fase-fase utama (disertai dengan deskripsi problem-problemnya) ke dalam daftar berbagai pekerjaan dan algoritma.
Ringkasan dari berbagai pekerjaan dalam pra-pemrosesan data dan
metode-metode yang bisa digunakan
|
||
Tugas utama
|
Sub-tugas
|
Metode yang popular
|
Konsolidasi data (Data consolidation)
|
Mengakses dan mengumpulkan data
Memilih dan memfilter data
Mengintegrasikan dan menyatukan data
|
SQL queires, software agents, web services
Domain expertise, SQL queries, statistical tests
SQL queries, domain expertise, ontology-driven data mapping
|
Pembersihan data (Data cleaning)
|
Mengurusi nilai-nilai yang hilang/kosong dalam data
Mengidentifikasi dan mengurangi noise dalam data
Menemukan dan menghilangkan data yang salah
|
Mengisi nilai yang hilang (imputations) dengan nilai yang tepat (mean,
median, min/max, mode, etc); menulis ulang nilai yang hilang dengan konstanta
seperti “ML”; menghapus baris pada nilai yang hilang; dibiarkan saja.
Mengidentifikasi nilai-nilai yang seharusnya tidak seharusnya di
dalam data dengan teknik-teknik statistic sederhana (seperti rerata dan standard
deviasi) atau dengan analisa kluster; setelah diidentifikasi bisa
menghilangkan nilai-nilai tersebut atau memodifikasi/menghaluskan nya dengan ‘binning’,
‘regression’, atau ‘simple averages’.
Mengidentifikasi nilai-nilai yang salah dalam data (selain data yang
tidak seharusnya), seperti nilai-nilai ganjil, label-label kelas yang tidak
konsisten, distribusi ganjil; setelah teridentifikasi, gunakan domain expertise
9si ahlinya dari domain tersebut) untuk membetulkan nilai-nilai tersebut atau
menghapus baris-baris yang memiliki nilai yang salah tersebut.
|
Transformasi data (Data transformation)
|
Me-normalisasi-kan data
Me-diskrit-kan atau me-angregasi-kan data
Me-konstruksi atribut-atribut baru
|
Mengurangi ‘kisaran’ nilai dalam setiap variabel yang bernilai numerik
menjadi kisaran standard (misalnya 0 ke 1 atau -1 ke +1) dengan menggunakan
berbagai teknik normalisasi dan scalilng)
Bila diperlukan, mengonversi berbagai variabel numeric menjadi bentuk
diskrit dengan menggunakan kisaran frekwensi berbasis teknik-teknik binning;
untuk variabel-variabel kategori mengurangi jumlah nilai dengan menerapkan
hirarki yang tepat.
Membuat turunan variabel-variabel yang baru dan lebih informative dari
variabel yang sudah ada dengan menggunakan berbagai fungsi matematika
(sesederhana penjumlahan dan perkalian atau sekompleks kombinasi hybrid
logaritma.
|
Pengurangan data (Data reduction)
|
Mengurangi jumlah atribut
Mengurangi jumlah baris
Menyeimbangkan data yang miring (‘skewed data’)
|
Analisa komponen utama, analisa komponen bebas, chi-square testing,
analisa korelasi, dan induksi pohon keputusan
sampling acak, sampling bertingkat-tingkat, expert-knowledge-driven
purposeful sampling
oversample (mengambil sampling yang agak banyak diatas kebutuhan)
pada data yang sedikit atau under sample (mengambil sampling sedikit saja di bawah kebutuhan) pada bagian data yang
banyak
|
Langkah 4: Pembuatan model (model building)
Dalam tahap ini, berbagai macam teknik pemodelan dipilih dan diterapkan ke dataset yang sudah disiapkan untuk mengatasi kebutuhan bisnis tertentu. Tahap pembuatan model juga mencakup penilaian dan analisa komparatif dari berbagai model yang dibangun. Karena tidak ada satupun model yang secara universal dianggap sebagai metode atau algoritma yang terbaik untuk pekerjaan DM, kita harus menggunakan berbagai macam jenis model dan eksperimentasi dan strategi penilaian yang sudah didefinisikan dengan baik untuk mengetahui metode terbaik yang sesuai dengan maksud yang sudah ditentukan. Bahkan untuk metode atau algoritma tunggal sekalipun, sejumlah parameter perlu dikalibrasi untuk mendapatkan hasil yang maksimal. Beberapa metode bisa saja memiliki syarat-syarat tertentu mengenai bagaimana data akan di-format; karena itulah seringkali diperlukan kembali ke langkah sebelumnya ke tahap ‘persiapan data’ (data preparation).
Tergantung pada kebutuhan bisnis, pekerjaan DM bisa merupakan suatu jenis prediksi/prediction (entah klasifikasi/classification atau regresi/regression), asosiasi (association), atau clustering. Setiap pekerjaan DM bisa menggunakan bermacam metode dan algoritma DM. Beberapa metode DM tersebut sudah dujelaskan pada seri sebelumnya, dan beberapa algoritma yang terpopuler, seperti ‘decision trees’ untuk ‘classification’ (klasifikasi), ‘k-means’ untuk clustering, dan algoritma ‘Apriori’ untuk ‘association rule mining’, akan dijelaskan pada seri berikutnya.
Langkah 5: Pengujian dan evaluasi (testing and evaluation)
Pada langkah 5 ini, model yang sudah dibuat diuji dan dievaluasi keakuratan dan ‘generalitas’-nya. Tahap ini mengukur sejauh mana model yang sudah dipilih memenuhi sasaran-sasaran bisnis dan bila demikian, sejauh manakah itu (apakah perlu lebih banyak model untuk dibuat dan diukur). Pilihan lain adalah melakukan pengujian pada model yang sudah dibuat dengan scenario riil (real-world) bila waktu dan budget mengijinkan. Meskipun hasil dari model-model yang sudah dikembangkan diharapkan berkaitan dengan tujuan awal, tetapi temuan-temuan lainnya yang tidak terkait dengan tujuan awal dan mungkin saja juga menyingkap informasi tambahan atau petunjuk bagi masa depan seringkali ditemukan.
Pengujian dan evaluasi ini merupakan pekerjaan yang sangat penting dan menantang. Tidak ada ‘value’ yang ditambahkan pada pekerjaan DM ini hingga ‘value’ bisnis yang dihasilkan dari pola-pola knowledge yang sudah ditemukan diidentifikasi dan dikenali. Menentukan ‘value’ bisnis dari pola-pola knowledge yang telah ditemukan agak mirip dengan bermain teka-teki. Pola-pola knowledge yang sudah diekstrak merupakan potongan-potongan teka-teki yang perlu diletakkan bersama-sama dalam konteks tujuan bisnis tertentu. Keberhasilan pengerjaan identifikasi ini bergantung pada interaksi antara para analis data, analis bisnis (business analysts) dan pembuat keputusan (decision makers) misalnya para manajer bisnis. Karena para analis data mungkin saja tidak paham secara penuh mengenai tujuan-tujuan dilakukannya DM dan apa maksudnya bagi bisnis sedangkan para analis bisnis dan pembuat keputusan mungkin saja tidak memiliki pengetahuan teknis untuk menginterpretasikan hasil-hasil solusi matematis yang canggih, karena itu interaksi diantara mereka sangatlah diperlukan. Supaya menginterpretasikan pola-pola knowledge dengan benar, seringkali digunakan berbagai macam tabulasi dan teknik-teknik visualisasi (misalnya table-tabel pivot, tabulasi silang dari berbagai temuan, diagram pie, diagram batangm box plots, scatterplots).
Langkah 6: Penyebaran (deployment)
Pembuatan dan penilaian terhadap berbagai model bukanlah akhir dari project DM. Meskipun maksud model adalah untuk memiliki eksplorasi sederhana terhadap data, knowledge yang didapat dari eksplorasi tersebut perlu diatur dan disajikan dengan cara yang bisa dipahami oleh ‘end user’ dan bisa diambil manfaatnya. Bergantung pada berbagai persyaratannya, tahap ‘deployment’ ini bisa sangat sederhana seperti halnya membuat ‘report’ atau bisa juga sangat rumit seperti mengimplementasikan suatu proses DM yang berulang diseluruh korporat. Dalam berbagai kasus, sang pelangganlah, dan bukan sang analis, yang melakukan tahap-tahap ‘deployment’. Namun demikian, sekalipun sang analis tidak melakukan usaha ‘deployment’, sangatlah penting bagi pengguna untuk memahami dari depan mengenai tindakan apa saja yang perlu dilakukan supaya benar-benar memanfaatkan model yang sudah dibuat.
Tahap ‘deployment’ mungkin juga meliputi berbagai aktivitas ‘maintenance’ pada model yang sudah digunakan. Karena semua yang terkait dengan bisnis pasti mengalami perubahan, jadi data yang mencerminkan berbagai aktivitas bisnis tersebut juga berubah. Seiring dengan berjalannya waktu, model-model (dan berbagai pola yang tertanam bersamanya) yang dibuat berdasarkan pada data lama menjadi using, tidak relevan, atau menyesatkan. Karena itu proses ‘monitoring dan maintenance’ terhadap model merupakan hal yang penting bila hasil-hasil DM menjadi bagian penting dari bisnis sehari-hari. Persiapan yang cermat dalam strategi ‘maintenance’ akan membantu menghindarkan dari penggunaan jangka panjang yang tak perlu dan hasil DM yang salah. Untuk memonitor ‘deployment’ hasil-hasil DM, project tersebut perlu rencana detil mengenai proses monitoring, yang mungkin saja bukan hal yang sepele untuk model-model DM yang kompleks.
Beberapa proses dan methodologi standard lainnya dalam DM
Supaya bisa diterapkan dengan sukses, suatu kajian DM haruslah dilihat sebagai suatu proses yang mengikuti suatu methodology standard daripada sebagai sekumpulan teknik dan tool software otomatis. Selain CRISP-DM, ada satu methodology terkenal lainnya yang dikembangkan oleh ‘SAS Institute’, yang disebut dengan SEMMA. Singkatan SEMMA adalah ‘Sample, Explore, Modify, Model, and Assess’.
Dimulai dengan sampel data yang secara statistik dianggap representative, SEMMA memudahkan menerapkan teknik-teknik visualisasi dan statistik yang bersifat mencari atau menjelajah, memilih dan men-transform variabel-variabel prediksi yang paling signifikan, me-model-kan variabel-variabel untuk mem-prediksi berbagai hasil, dan men-konfirmasi keakurasian suatu model. Penyajian SEMMA dalam bentuk gambar bisa dilihat dibawah ini:
 |
| Proses DM SEMMA |
Dengan menilai hasil di setiap tahap dalam proses SEMMA, sang pembuat model bisa menentukan bagaimana me-model pertanyaan-pertanyaan baru yang dipicu oleh hasil-hasil proses sebelumnya, dan dengan demikian kembali lagi ke fase eksplorasi untuk penyaringan lanjutan dari data; yakni, seperti halnya pada CRISP-DM, SEMMA didorong oleh siklus eksperimentasi yang sangat iteratif. Perbedaan utama antara CRISP-DM dan SEMMA adalah bahwa CRISP-DM memiliki pendekatan ke project DM yang lebih komprehensif termasuk pemahaman terhadap bisnis dan data yang relevan, sementara SEMMA secara implisit beranggapan bahwa tujuan dan sasaran project DM dan berbagai sumber data nya telah diidentifikasi dan dipahami sebelumnya.
Beberapa praktisi pada umumnya menggunakan istilah ‘knowledge discovery in databases (KDD)’ sebagai sinonim DM. Fayyad et al. (1996) mendefinisikan ‘knowledge discovery in databases’ sebagai suatu proses menggunakan metode-metode DM untuk menemukan informasi dan pola-pola yang berguna di dalam data, dimana hal ini merupakan kebalikan dari DM, yang menggunakan berbagai macam algoritma untuk mengidentifikasi berbagai pola di dalam data yang diturunkan melalui proses KDD. KDD adalah suatu proses yang komprehensif yang mencakup DM. Input ke proses KDD terdiri dari data organisasi. Data warehouse (DW) korporat memungkinkan KDD untuk diimplementasikan secara efisien karena DW menyediakan satu sumber tunggal untuk penggalian data (DM). Dunham (2003) meringkas proses KDD sebagai proses yang berisi langkah-langkah berikut: pemilihan data (data selection), pra-pemrosesan data (data preprocessing), transformasi data (data transformation), penggalian data (data mining), dan interpretasi/evaluasi (interpretation/evaluation). Gambar di bawah berikut menunjukkan hasil polling terhadap pertanyaan: Methodolgi apakah yang anda gunakan untuk data mining? (polling yang diadakan oleh kdnuggets.com pada agustus 2007).
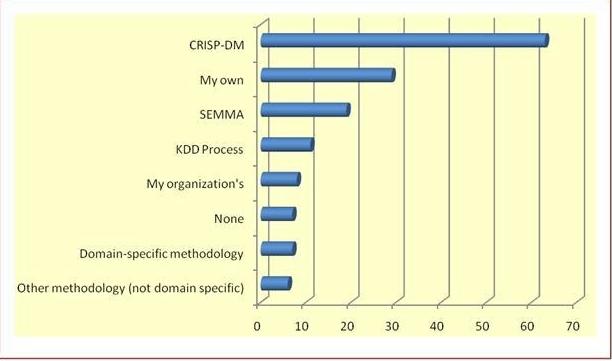 |
| Ranking penggunaan proses/methodologi dalam data mining |
Daftar link terkait seri data mining for business intelligence:
- Pendahuluan
- Definisi, karakteristik, dan manfaat
- Bagaimana cara kerja data mining
- Penerapan-penerapan Data Mining
- Proses dalam Data Mining
- Metode-metode dalam Data Mining
- Berbagai Tool Software Data Mining
- Beberapa mitos dan blunder dalam data mining
Comments
Post a Comment